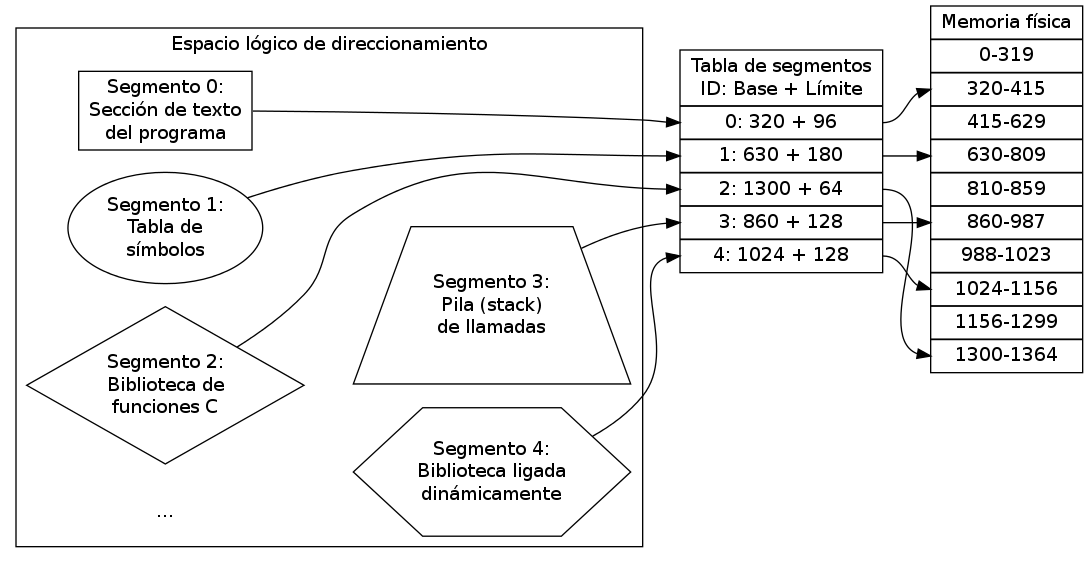
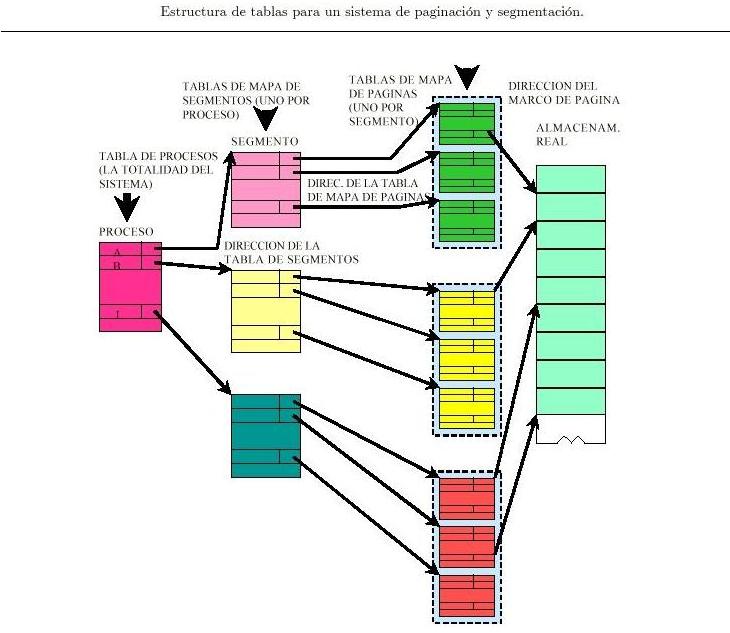
La comunicación es una función básica de los sistemas operativos que provee un mecanismo que permite a los procesos comunicarse y sincronizarse entre ellos, normalmente a través de un sistema de bajo nivel.
En un sistema, los procesos pueden ejecutarse independientemente o cooperando entre sí. Los intérpretes de comandos son ejemplos típicos de procesos que no precisan la cooperación de otros para realizar sus funciones. En cambio, los procesos que sí cooperan necesitan comunicarse entre sí para poder completar sus tareas.
La comunicación entre procesos puede estar motivada por la competencia o el uso de recursos compartidos o porque varios procesos deban ejecutarse sincronizadamente para completar una tarea.
Problemas de la sección critica:
El problema de la sección crítica es uno de los problemas que con mayor frecuencia aparece cuando se ejecutan procesos concurrentes.
Para entender un poco mejor el concepto se presenta el siguiente ejemplo: Se tiene un Sistema Operativo que debe asignar un identificador de proceso (PID) a dos procesos en un sistema multiprocesador.
Cuando el SO realiza esta acción en dos procesadores de forma simultánea sin ningún tipo de control, se pueden producir errores, ya que se puede asignar el mismo PID a dos procesos distintos.
Este problema se debe a que constituyen una sección crítica que debe ejecutarse en forma atómica, es decir, de forma completa e indivisible y ningún otro proceso podrá ejecutar dicho código mientras el primero no haya acabado su sección.
Solución a la sección crítica:
Para resolver el problema de la sección crítica es necesario utilizar algún mecanismo de sincronización que permita a los procesos cooperar entre ellos sin problemas. Este mecanismo debe proteger el código de la sección crítica y su funcionamiento básico es el siguiente:
Cada proceso debe solicitar permiso para entrar en la sección crítica, mediante algún fragmento de código que se denomina de forma genérica entrada en la sección crítica.
Cuando un proceso sale de la sección critica debe indicarlo mediante otro fragmento de código que se denomina salida de la
Sección crítica. Este fragmento permitirá que otros procesos entren a ejecutar el código de la sección crítica.
Cualquier solución que se utilice para resolver este problema debe cumplir los tres requisitos siguientes:
Exclusión mutua: Si un proceso está ejecutando código de la sección crítica, ningún otro proceso lo podrá hacer.
Progreso: Si ningún proceso está ejecutando dentro de la sección crítica, la decisión de qué proceso entra en la sección se hará sobre los procesos que desean entrar.
Espera acotada: Debe haber un límite en el número de veces que se permite que los demás procesos entren a ejecutar código de la
Sección crítica después de que un proceso haya efectuado una solicitud de entrada y antes de que se conceda la suya.
Para solucionar las condiciones de competencia se implementó un modelo para prohibir que dos procesos accedan al mismo recurso.
El modelo en cuestión se denomina exclusión mutua.
Exclusión mutua de espera ocupada
Los algoritmos de exclusión mutua se usan en programación concurrente para evitar el uso simultáneo de recursos comunes, como variables globales, por fragmentos de código conocidos como secciones críticas.
La mayor parte de estos recursos son las señales, contadores, colas y otros datos que se emplean en la comunicación entre el código que se ejecuta cuando se da servicio a una interrupción y el código que se ejecuta el resto del tiempo. Se trata de un problema de vital importancia porque, si no se toman las precauciones debidas, una interrupción puede ocurrir entre dos instrucciones cualesquiera del código normal y esto puede provocar graves fallos.
La técnica que se emplea por lo común para conseguir la exclusión mutua es inhabilitar las interrupciones durante el conjunto de instrucciones más pequeño que impedirá la corrupción de la estructura compartida (la sección crítica). Esto impide que el código de la interrupción se ejecute en mitad de la sección crítica.
Requisitos para la exclusión mutua:
- Sólo un proceso, de todos los que poseen secciones críticas por el mismo recurso compartido, debe tener permiso para entrar en ella en un momento dado.
- Un proceso que se interrumpe en una sección no crítica debe hacerlo sin interferir con los otros procesos.
- Un proceso no debe poder solicitar acceso a una sección crítica para después ser demorado indefinidamente, no puede permitirse el interbloqueo o la inanición.
- Si ningún proceso está en su sección crítica, cualquier proceso que solicite entrar en la suya debe poder hacerlo sin demora.
- No se debe suponer sobre la velocidad relativa de los procesos o el número de procesadores.
- Un proceso permanece en su sección crítica por un tiempo finito.
- Una manera de satisfacer los requisitos de exclusión mutua es dejar la responsabilidad a los procesos que deseen ejecutar concurrentemente. Tanto si son programas del sistema como de aplicación, los procesos deben coordinarse unos con otros para cumplir la exclusión mutua, sin ayuda del lenguaje de programación o del sistema operativo. Estos métodos se conocen como soluciones por software.
Para solucionar el problema de la exclusión mutua vamos a tener tres tipos de soluciones:
- Soluciones software.
- Soluciones hardware.
- Soluciones aportadas por el Sistema Operativo
Algunos ejemplos de algoritmos clásicos de exclusión mutua son:
- El algoritmo de Dekker.
- El algoritmo de Peterson.
Bloqueo y Desbloqueo
Los bloqueos pueden ser resueltos por el sistema operativo aunque en ocasiones pueden parar la maquina. Un conjunto de procesos se bloquea si cada proceso del conjunto espera un evento que solo puede ser provocado por otro proceso del mismo conjunto. Puesto que todos los procesos están esperando ninguno de ellos realizará el evento que pueda despertar a los demás y todos los procesos esperaran por siempre.
Cuando los recursos son compartidos entre usuarios:
Pueden producirse interbloqueos en los cuales los procesos de algunos usuarios nunca podrán llegar a su término. Se debe considerar la prevención, evitación, detección y recuperación del interbloqueo y la postergación indefinida, que se da cuando un proceso, aunque no esté interbloqueado, puede estar esperando por un evento que probablemente nunca ocurrirá.
En algunos casos:
- El precio de liberar interbloqueos en un sistema es demasiado alto.
- El precio de liberar interbloqueos en un sistema es demasiado alto. Permitir el interbloqueo podría resultar catastrófico.
Los sistemas de cómputos tienen muchos recursos que solo pueden ser utilizados por un proceso a la vez: Ej.: impresoras, unidades de cinta, espacio de la tabla de nodos-i.
Los S. O. tienen la capacidad de otorgar temporalmente a un proceso el acceso exclusivo a ciertos recursos.
Frecuentemente un proceso necesita el acceso exclusivo no solo a un recurso, sino a varios.
Los recursos pueden ser de dos tipos:
Apropiables.
Este tipo de recurso, es aquel que si no esta siendo utilizado por un proceso, el sistema operativo en caso de que otro proceso lo necesite se lo asigna a este proceso. Un ejemplo de este recurso es la memoria.
No apropiables.
Este tipo de recurso, es aquel es si un proceso lo esta necesitando, en este caso no se libera a menos que el proceso lo libere. Un ejemplo de este es la impresora.
Semáforo
Un semáforo es un tipo abstracto de dato, y como tal, su definición requiere especificar sus dos atributos básicos:
- Conjunto de valores que puede tomar.
- Conjunto de operaciones que admite.
Un semáforo tiene también asociada una lista de procesos, en la que se incluyen todos los procesos que se encuentra suspendidos a la espera de acceder al mismo.
Los semáforos admiten dos operaciones:
- Operación Wait: Si el valor del semáforo no es nulo, esta operación decrementa en uno el valor del semáforo. En el caso de que su valor sea nulo, la operación suspende el proceso que lo ejecuta y lo ubica en la lista del semáforo a la espera de que deje de ser nulo el valor.
- Operación Signal: Incrementa el valor del semáforo, y en caso de que haya procesos en la lista de espera del semáforo, se activa uno de ellos para que concluya su operación Wait.
Lo importante del semáforo es que se garantiza que la operación de chequeo del valor del semáforo, y posterior actualización según proceda, es siempre segura respecto a otros accesos concurrentes.
Semáforo binario
Podemos usar semáforos binarios para abordar el problema de la sección crítica en el caso de múltiples procesos. Los procesos comparten un semáforo, mutex, inicializado con el valor 1. Cada proceso P.
Semáforo de conteo
Los semáforos contadores se pueden usar para controlar el acceso a un determinado recurso formado por un número finito de instancias. El semáforo se inicializa con el número de recursos disponibles. Cada proceso que desee usar un recurso ejecuta una operación wait () en el semáforo (con decremento en la cuenta). Cuando un proceso libera un recurso, ejecuta una operación signal() (incrementando la cuenta). Cuando la cuenta del semáforo llega a 0, todos los recursos estarán en uso. Después, los procesos que deseen usar un recurso se bloquearan hasta que la cuenta sea mayor que 0.
Monitor
Un monitor es una colección de procedimientos, variables y estrucuturas de datos que se agrupan en un tipo especial de módulo o paquete. Los procesos pueden invocar los procedimientos de un monitor en el momento en que deseen, pero no pueden acceder directamente a las estrucuturas de datos internas del monitor desde procedimientos declarados afuera del mismo.
Los monitores poseen una propiedad especial que los hace útiles para lograr la exclusión mutua: solo un proceso puede estar activo en un monitor en un momento dado. Los monitores son una construcción de lenguaje de programación, asi que el compilador sabe que son especiales y puede manejar las llamadas a procedimientos de monitos de una forma diferente a como maneja otras llamadas a procedimientos. Por lo regular, cuando un proceso invoca un procedimiento de monitor, las primeras instrucciones del procedimiento verifican si hay algun otro proceso activo en ese momento dentro del monitor. Si así es, el proceso invocador se suspende hasta que el otro proceso abandona el monitor. Si ningún otro proceso está usando el monitor, el proceso invocador puede entrar.
Es responsabilidad del compilador implementar la exclusión mutua en las entradas a monitores, pero una forma común es usar un semáforo binario. Puesto que el compilador, no el programador, se esta encargando de la exclusion mutua, es mucho menos probable que algo salga mal. En cualquier caso, la persona que escribe el monitor no tiene que saber como el compilador logra la exclusión mutua; le basta con saber que si convierte todas las regiones criticas en procedimientos de monitor, dos procesos nunca podrán ejecutar sus regiones criticas al mismo tiempo.
Cuando un procedimiento de monitor descubre que no puede continuar (por ejemplo, si encuentra lleno el buffer) ejecuta WAIT (esperar) con alguna variable de condición digamos full! (lleno). Esta acción hace que el proceso invocador se bloquee, y también permite la entrada de otro proceso al que antes se le había impedido entrar en el monitor.
Este otro proceso puede despertar a su "compañero" dormido ejecutando SIGNAL (señal) con la variable de condición que su compañero está esperando. A fin de evitar la presencia de dos procesos activos en el monitor al mismo tiempo, necesitamos una regla que nos diga qué sucede después de ejecutarse SIGNAL. Hoare propuso dejar que el proceso recién despertado se ejecute, suspendiendo el otro. Brinch Hansen propuso sortear el problema exigiendo al proceso que ejecutó SIGNAL salir inmediatamente del monitor. Dicho de otro modo, una instrucción SIGNAL sólo puede aparecer como última instrucción de un procedimiento de monitor.
Transmisión de mensajes
Cuando los procesos interactúan unos con otros, se deben satisfacer dos requisitos básicos: la sincronización y la comunicación. Un método posible para ofrecer ambas funciones es el paso de mensajes. Su funcionalidad real se ofrece, normalmente, por medio de las primitivas send (destino, mensaje) y receive (origen, mensaje).
Un proceso envía información en forma de un mensaje a otro proceso designado como destino. Un proceso recibe información ejecutando la primitiva receive, que indica el proceso emisor (origen) y el mensaje.
Formato de mensajes
Depende de los objetivos del servicio de mensajería y de si el servicio ejecuta en un ordenador independiente o en un sistema distribuido. Para algunos S.O., los diseñadores han elegido mensajes cortos y de tamaño fijo para minimizar el procesamiento y el coste de almacenamiento. Si se va a pasar una gran cantidad de datos, los mismos pueden ponerse en un archivo y el mensaje simplemente hará referencia a este archivo. Una solución más flexible es permitir mensajes de longitud variable con un formato que incluya los campos: origen, destino, longitud del mensaje, información de control, tipo de mensaje y contenido del mensaje.
Problemas de la comunicación de procesos
Los 5 filósofos
En 1965 Dijkstra planteó y resolvió un problema de sincronización llamado el problema de la cena de los filósofos, que se puede enunciar como sigue. Cinco filósofos se sientan a la mesa, cada uno con un plato de espaghetti. El espaghetti es tan escurridizo que un filósofo necesita dos tenedores para comerlo. Entre cada dos platos hay un tenedor.
La vida de un filósofo consta de periodos alternos de comer y pensar. Cuando un filósofo tiene hambre, intenta obtener un tenedor para su mano derecha, y otro para su mano izquierda, cogiendo uno a la vez y en cualquier orden. Si logra obtener los dos tenedores, come un rato y después deja los tenedores y continúa pensando.
Lectores y escritores
Hay un objeto de datos(fichero de texto) que es utilizado por varios procesos, unos leen y otro que escribe.
Solo puede utilizar el recurso un proceso y solo uno, es decir, o bien un proceso estará escribiendo o bien leyendo, pero nunca ocurrirá simultáneamente (teniendo en cuenta que si no lo esta utilizando nadie, tendrá preferencia el escritor ante el lector).
Se considera a cada usuario (lector y escritor) como dos procesos y al fichero en cuestión como un recurso. De modo que, para que un proceso acceda al recurso que necesita, tenemos que considerar a cada usuario (lector y escritor) como dos semáforos. Estos semáforos son binarios y valen 0 si el recurso (fichero) está siendo utilizado por otro proceso y 1 si dicho recurso está disponible.